Configure Web App Tracker
Web App Tracker collects web logs from the history database of a browser. It reads the database and merges the contents to create a report of usages based on the configured web applications.
Before proceeding, make sure the Web App Tracker collection is activated.
Include or Exclude URLs to Track
- Windows
- macOS
-
Open
url_filterin the Configuration directory, which is by default inC:\Program Files\OpeniT\Core\Configuration.Notice that it contains instructions on how to edit the file and a list of URLs already included for initial data collection.
-
Configure the URL filter with the following syntax:
Command Syntax<use> = <regular_expression>where
<use>is either include or exclude, and<regular_expression>is any valid regular expression pertaining to a group or a specific URL.noteOnly URLs that match the specified pattern will be recorded. To track usage, at least one include pattern must be defined.
Use globs (
*) to match the URLs and page titles. Use#to comment.noteSpecify general elements first, followed by specific elements. Entries are processed sequentially, starting from the top.
-
Save the changes.
-
Open
url_filterin the Configuration directory, which is by default in/usr/local/openit/etc/.Notice that it contains instructions on how to edit the file and a list of URLs already included for initial data collection.
-
Configure the URL filter with the following syntax:
Command Syntax<use> = <regular_expression>where
<use>is either include or exclude, and<regular_expression>is any valid regular expression pertaining to a group or a specific URL.noteOnly URLs that match the specified pattern will be recorded. To track usage, at least one include pattern must be defined.
Use globs (
*) to match the URLs and page titles. Use#to comment.noteSpecify general elements first, followed by specific elements. Entries are processed sequentially, starting from the top.
-
Save the changes.
Recommended readings: Renaming Application Name for Collected URLs/Page Titles.
Configuring Browsers to Track for Data Collection
The Web App Tracker supports data collection from Google Chrome, Mozilla Firefox, and Microsoft Edge by default. The following are the supported browsers, along with their key counterparts.
| Browser | Key |
|---|---|
| Google Chrome | chrome |
| Microsoft Edge | edge |
| Mozilla Firefox | firefox |
| Internet Explorer | ie |
| Microsoft Edge Legacy | edge legacy |
- Windows
- macOS
-
Go to the scheduler directory, which is by default in
C:\Program Files\OpeniT\Core\Configuration\scheduler, and opencollect_browser-log.oconf. -
Locate
root.scheduler.jobs.collect_weblog.operations.argumentsand specify the browsers for which to collect usage data.collect_browser-log.oconf}
arguments
{
type=string
value=--target "${OpeniT.directories.temp}\PollCollector\Weblog" --interval PT1H --exe "${OpeniT.directories.bin}\openit_weblogpoller.exe" --timeout PT30M --module usageanalyzer --datatype webappbrowserlog --skip-onerror --key weblog --args --statusdir "\"${OpeniT.directories.temp}\"" --browsers chrome,firefox,ie"
}In this setup, only Google Chrome (
chrome), Mozilla Firefox (firefox), and Internet Explorer (ie) will be included for data collection. -
Save the changes.
-
Go to the scheduler directory, which is by default in
/usr/local/openit/etc/scheduler, and opencollect_browser-log-mac.oconf. -
Locate
root.scheduler.jobs.collect_weblog.operations.argumentsand specify the browsers for which to collect usage data.collect_browser-log-mac.oconf}
arguments
{
type=string
value=--target "${OpeniT.directories.temp}\PollCollector\Weblog" --interval PT1H --exe "${OpeniT.directories.bin}\openit_weblogpoller.exe" --timeout PT30M --module usageanalyzer --datatype webappbrowserlog --skip-onerror --key weblog --args --statusdir "\"${OpeniT.directories.temp}\"" --browsers safari,chrome,opera,firefox"
}In this setup, only Safari (
safari), Google Chrome (chrome), Opera (opera), and Mozilla Firefox (firefox) will be included for data collection. -
Save the changes.
Configuring Browser Usage Data Collection
- Windows
- macOS
-
Go to the scheduler directory, which is by default in
C:\Program Files\OpeniT\Core\Configuration\scheduler, and opencollect_browser-log.oconf. -
Locate and set
root.scheduler.jobs.collect_weblog.general.activetotrueto activate the collection of browser data.collect_browser-log.oconf}
general
{
active
{
type=bool
value=true -
Save the changes.
-
Go to the scheduler directory, which is by default in
/usr/local/openit/etc/scheduler, and opencollect_browser-log-mac.oconf. -
Locate and set
root.scheduler.jobs.collect_weblog.general.activetotrueto activate the collection of browser data.collect_browser-log-mac.oconf}
general
{
active
{
type=bool
value=true -
Save the changes.
Advanced Configuration
The collection runs hourly using a 5-minute sample interval by default. The primary data is then transferred to the server every night according to the client timezone for processing. To configure the intervals, locate the instances attribute under collect_weblog, preprocess_weblog, transfer_weblog_parsed, or transfer_weblog_raw in the same file and configure the attributes.
Refer to the Web Log Job Scheduler Instances Configuration table to learn about the attributes used for configuring web log data collection and transfer.
| Attribute Name | Accepted Value | Description |
|---|---|---|
| max-instances | Uint (e.g., 5, 8, 9) | The number of instances allowed to run at the same time. |
| max-handling | String (end-oldest, end-all-old, or end-new) | The action done upon reaching the maximum number of instances. Specify end-oldest to stop/kill the oldest instance and then start the new, specify end-all-old to stop/kill all running instances and then start the new, or specify end-new to not start the new instance. |
| end-timeout | Timespan (e.g., P30S, P5M, P1H) | The maximum waiting time before terminating a running instance. |
| quarantine | Timespan (e.g., P30S, P5M, P1H) | The waiting time before starting a new instance after a previous one. |
Open iT calculates the Elapsed Time value by multiplying the duration by the number of used applications (always 1). Without defined mappings, the default duration is set to 15 minutes for all applications, which will then be the minimum usage per application.
Verifying Web Log Data Collection
After configuration, you can verify that the data is collected and sent to the server by following these steps:
Quit Safari browser to save its recent logs/history.
- Windows
- macOS
-
Open a command prompt with Administrator level privileges.
-
Go to the bin directory, which is by default in
C:\Program Files\OpeniT\Core\bin, run the command:Command Syntaxcd <bin_dir>Examplecd C:\Program Files\OpeniT\Core\bin -
Run the command:
Command Syntaxopenit_pollcollector --target "${OpeniT.directories.temp}\PollCollector\Weblog" --interval PT1H --exe "${OpeniT.directories.bin}\openit_weblogpoller.exe" --timeout PT30M --module usageanalyzer --datatype webappbrowserlog --skip-onerror --key weblog --args --statusdir "${OpeniT.directories.temp}" --browsers chrome,edge,firefox"Exampleopenit_pollcollector --target "C:\ProgramData\OpeniT\Data\temp\PollCollector\Weblog" --interval PT1H --exe "C:\Program Files\OpeniT\Core\bin\openit_weblogpoller.exe" --timeout PT30M --module usageanalyzer --datatype webappbrowserlog --skip-onerror --key weblog --args --statusdir "\"C:\ProgramData\OpeniT\Data\temp\"" --browsers chrome,edge,firefox" -
Verify that the temp directory, which is by default in
C:\ProgramData\OpeniT\Data\temp, contains a Weblog directory containing.datafiles containing raw browser usage data.
-
Go to the bin directory, which is by default in
/usr/local/openit/bin, run the command:Command Syntaxcd <bin_dir>Examplecd /usr/local/openit/bin -
Run the command:
Command Syntax./openit_pollcollector --target "${OpeniT.directories.temp}/PollCollector/Weblog" --interval PT1H --exe "${OpeniT.directories.bin}/openit_weblogpoller" --timeout PT30M --module usageanalyzer --datatype webappbrowserlog --skip-onerror --key weblog --args --statusdir "\"${OpeniT.directories.temp}\"" --browsers chrome,opera,firefox"Example./openit_pollcollector --target "usr/local/openit/temp/PollCollector/Weblog" --interval PT1H --exe "/usr/local/openit/bin/openit_weblogpoller" --timeout PT30M --module usageanalyzer --datatype webappbrowserlog --skip-onerror --key weblog --args --statusdir "\"usr/local/openit/temp/\"" --browsers chrome,opera,firefox" -
Verify that the temp directory, which is by default in
/usr/local/openit/temp, contains a Weblog directory containing.datafiles containing raw browser usage data.
Troubleshooting
Missing URL or Websites in the Reports
Problem
There are missing URL(s) or website(s) in the generated report.
Resolution
- Windows
- macOS
Make sure that the URL pattern, expected in the report, is included and does not match any of the exclude patterns in the url_filter in the Configuration directory, which is by default in C:\Program Files\OpeniT\Core\Configuration.
Make sure that the URL pattern, expected in the report, is included and does not match any of the exclude patterns in the url_filter in the Configuration directory, which is by default in /usr/local/openit/etc/.
Archive is not Created in the Server
Problem
There are no archive files created in the Core Server even after collection.
Resolution
- Windows
- macOS
Make sure that the transfer_weblog_parsed and transfer_weblog_raw jobs in collect_browser-log.oconf in the scheduler directory, which is by default in C:\Program Files\OpeniT\Core\Configuration\scheduler, are set to true.
transfer_weblog_parsed
{
about
{
type=string
value=Transfer browser log data to server
}
general
{
active
{
type=bool
value=true
}
transfer_weblog_raw
{
about
{
type=string
value=Transfer browser log data to server
}
general
{
active
{
type=bool
value=true
}
Make sure that the transfer_weblog_parsed and transfer_weblog_raw jobs in collect_browser-log-mac.oconf in the scheduler directory, which is by default in /usr/local/openit/etc/scheduler, are set to true.
transfer_weblog_parsed
{
about
{
type=string
value=Transfer browser log data to server
}
general
{
active
{
type=bool
value=true
}
transfer_weblog_raw
{
about
{
type=string
value=Transfer browser log data to server
}
general
{
active
{
type=bool
value=true
}
Additionally, attempt to verify the collection of raw browser usage data. If data is not created, it may indicate that there is no recent browser history usage from any of the supported browsers.
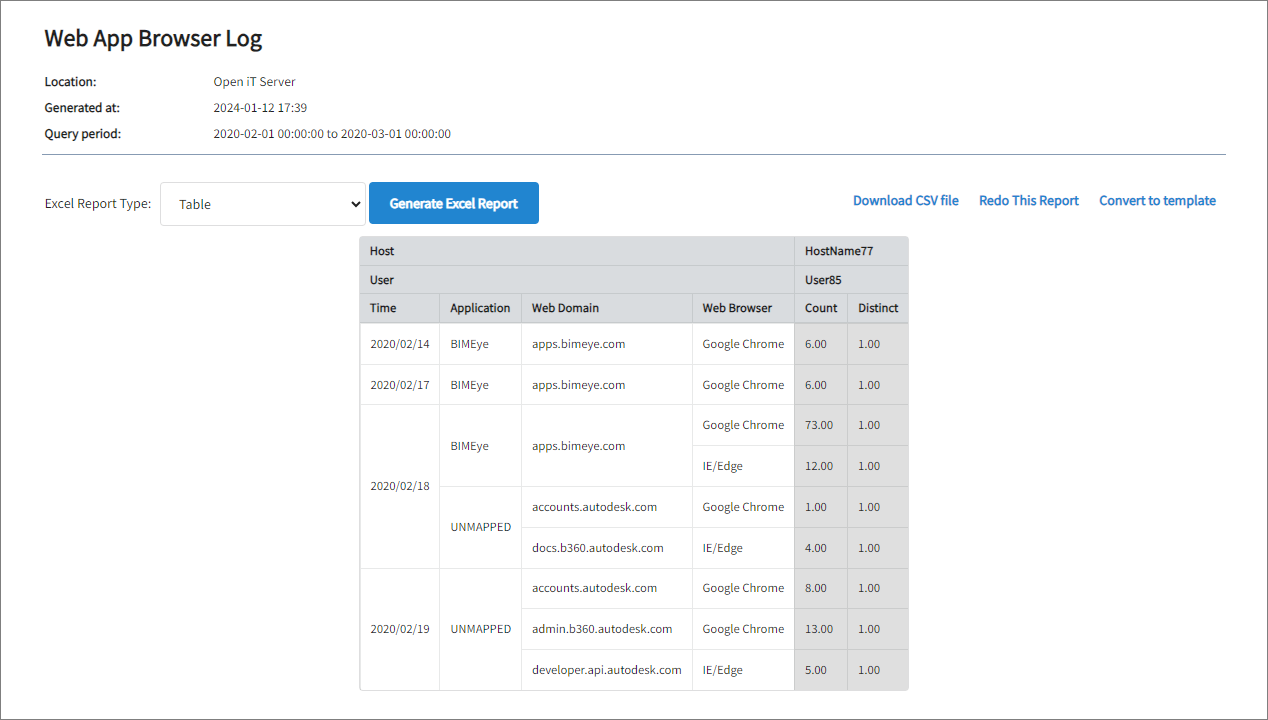
Sample Report
Web App Browser Log
This report is generated using data type (120) Web App Browser Log.